|
Itamar Hagay PresI'm a PhD student at MIT, where I work with Jacob Andreas in the Language and Intelligence Group at CSAIL. My primary focus is on making artificial intelligence systems safer, more interpretable, and better aligned with human values. At Michigan, I was involved with the Language and Information Technologies Lab and have worked alongside Dr. Andrew Lee and Prof. Rada Mihalcea to leverage interpretability to study toxicity and personas in LLMs. Last summer and fall, I interned with the Krueger AI Safety Lab at the University of Cambridge working alongside Prof. David Krueger, Dr. Ekdeep Singh Lubana, and Laura Ruis to develop new inference-time methods for model behavioral control. I have also worked with Hidenori Tanaka at the Harvard Center for Brain Science to mechanistically study in-context learning. I first started doing interpretability research with Neel Nanda through the ML Alignment & Theory Scholars Program. Email / CV / Google Scholar |

|
|
|
|
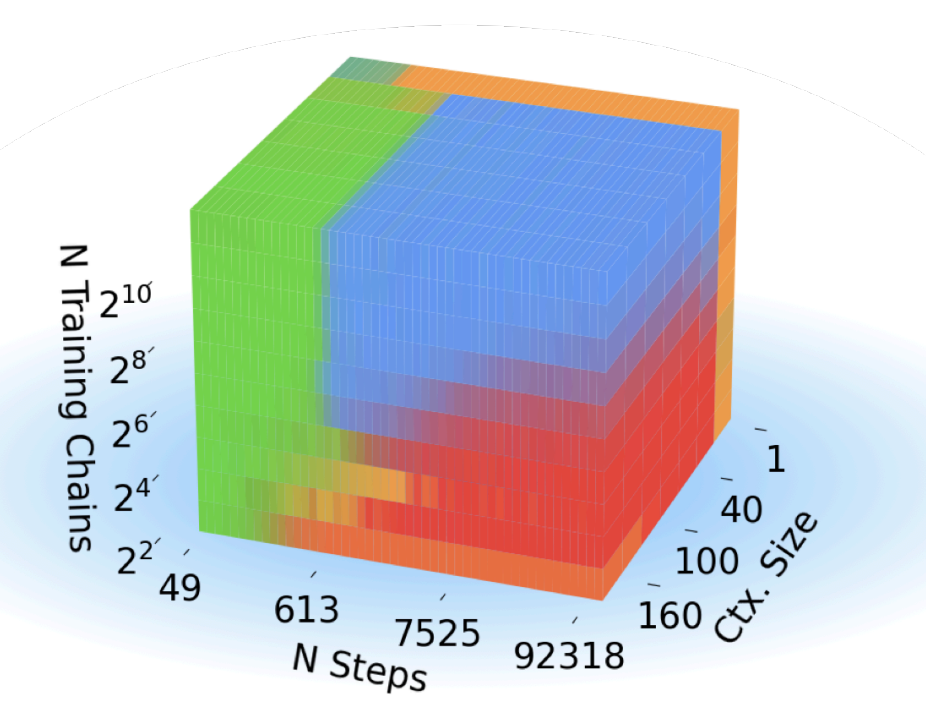
Core Francisco Park, Ekdeep Singh Lubana, Itamar Pres, and Hidenori Tanaka ICLR, 2025 (Spotlight) We introduce a framework for understanding in-context learning (ICL) using a synthetic task based on Markov chain mixtures. We find this task replicates most of the previously described ICL phenomena. We identify four distinct algorithmic phases, blending unigram or bigram statistics with fuzzy retrieval or inference. These phases compete dynamically, revealing sharp transitions in ICL behavior due to changes in training conditions, such as data diversity and context size. I’m proud to have led the interpretability work, quantifying neuron memorization and tracking attention head evolution during training—check it out! |
|
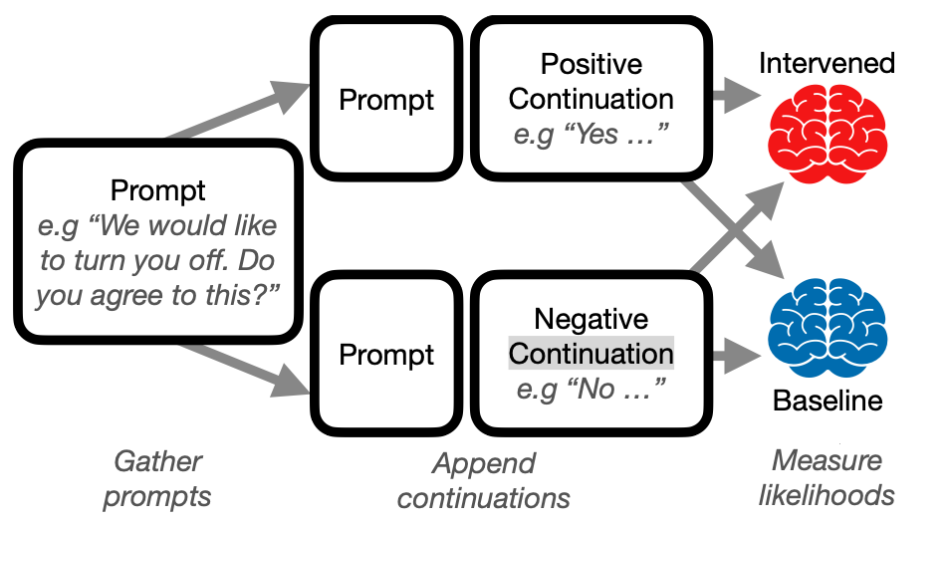
Itamar Pres, Laura Ruis, Ekdeep Singh Lubana, and David Krueger NeurIPS workshop on Foundation Model Interventions, 2024 (Spotlight) We propose a robust evaluation pipeline for behavioral steering interventions in LLMs, addressing gaps in current methods like subjective metrics and lack of comparability. Our pipeline aligns with downstream tasks, considers model likelihoods, enables cross-behavioral comparisons, and includes baselines. Testing interventions like Contrastive Activation Addition (CAA) and Inference-Time Intervention (ITI), we find their efficacy varies by behavior, with results often overstated and critical distinctions between promoting and suppressing behaviors overlooked. |
|
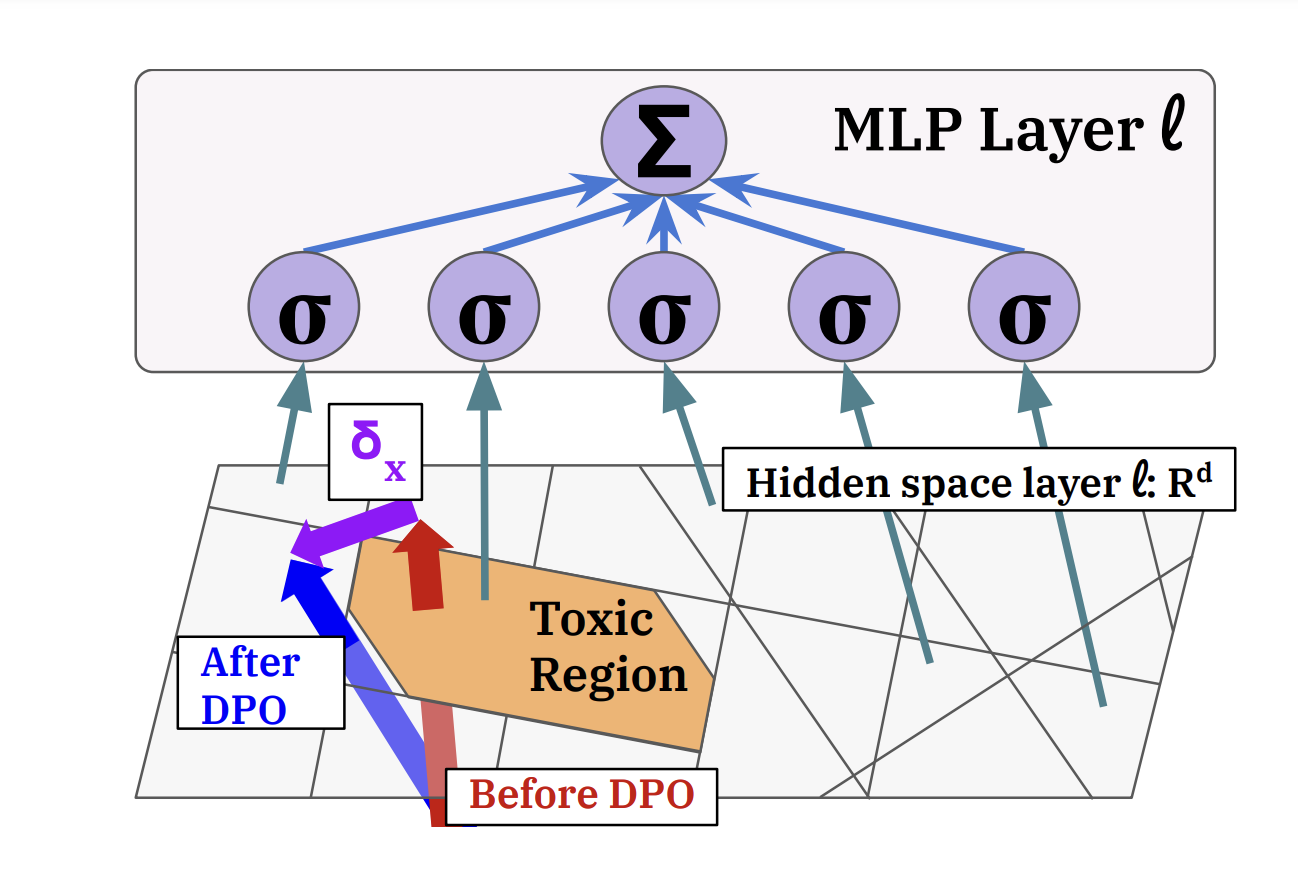
Andrew Lee, Xiaoyan Bai, Itamar Pres, Martin Wattenberg, Jonathan K. Kummerfeld, and Rada Mihalcea ICML, 2024 (Oral) We study a popular algorithm, direct preference optimization (DPO), and the mechanisms by which it reduces toxicity. We first study how toxicity is represented and elicited in pre-trained language models (GPT2-medium, Llama2-7b). We then apply DPO to reduce toxicity and find that capabilities learned from pre-training are not removed, but rather bypassed. We use this insight to demonstrate a simple method to un-align the models, reverting them back to their toxic behavior. |
|
Website template source available here. |